|
Software estadístico y econométrico En esta página explico cuáles son las opciones básicas que tenemos en cuanto a software estadístico y econométrico, lenguajes de programación para la modelización económica y literatura estadística y econométríca. Todos los programas estadísticos o econométricos ofrecen funciones matemáticas ya programadas a las que se puede acceder mediante comandos o menús (que nos ahorran aprendernos los comandos). Esto es lo que se conoce como "canned-packages" o programas "enlatados". La gran aportación de estos programas está en que facilitan el uso de la econometría, abstrayendo al usuario de las fórmulas, que no tienen que recordarse cada vez que se hace una operación (un solo comando puede estar activando decenas de complejos algoritmos matemáticos). Dos son las desventajas. La primera está en que facilita la aparición de aprendices de brujo, poniendo un peligroso arsenal en manos de personas que no saben qué están haciendo exactamente. La segunda es que si se desarrollan nuevos test el programa en cuestión no los incorporará, y su inclusión requerirá tiempo (aparte que el usuario puede verse obligado a pagar por la actualización). Por esas causas estos programas han buscado formas de añadir fácilmente funcionalidades, desarrolladas por la propia empresa o por los usuarios mediante un lenguaje de programación. Un ejemplo es Stata. Frente a ese modelo se ha desarrollado otro basado precisamente en lenguajes de programación especializados. Los programas construidos en torno a esos lenguajes permiten al usuario elaborar por sí mismo los algoritmos de cálculo. Además, se puede incorporar cualquier nuevo avance teórico, e incluso experimentar. Los usuarios también pueden compartir en este caso módulos y librerías, y se han habilitado en muchos casos procedimientos de comprobación de la calidad de este material. Un ejemplo es R. Como se ve, ambos modelos tienden a converger, y casi todos los programas ofrecen funciones ya preparadas que se pueden invocar con facilidad, más un lenguaje de programación y algún mecanismo para intercambiar y compartir esas programaciones y hacerlas fácilmente utilizables por cualquiera. En suma, los programas "enlatados" han añadidos lenguajes especializados de programación. En último término las variables más importantes a considerar son las características del lenguaje de programación (si la sintaxis es cómoda, si está extendido su uso, si hay documentación) y el coste (si hablamos de un programa "de pago" o de aplicaciones gratuitas, open source o bajo alguna licencia más o menos libre). El problema de la programación abierta a todos y de la facilidad de compartir "módulos" es que multiplican los problemas de fiabilidad en los cálculos. Pero incluso nuestros programas "de pago" favoritos pueden dar resultados falsos simplemente porque aplican el procedimiento de cálculo equivocado para los datos de que disponemos. Decimos equivocados teniendo en cuenta que la aritmética de los ordenadores no es la de "papel y lápiz". Estos errores pueden conocerse mediante baterías de test que ofrecen resultados de validez garantizada con los que comparar. Pero hay muchas funcionalidades para las que no se han desarrollado aún tests, y es fácil comprobar que distintos programas ofrecen distintos resultados, algunos muy disímiles, por lo que no sabemos qué resultado es el correcto (o cuáles son aceptables). Es más, en muchos artículos publicados no se dice qué software (o qué algoritmo) se ha empleado, por lo que no hay forma de saber si los resultados expuestos son correctos o no. Es un problema grave en potencia. Un articulo excelente sobre el tema, que todos deberían conocer, es McCullough, B.D. and Vinod, H.D. (1999): "The Numerical Reliability of Econometric Software", Journal of Economic Literature, vol. 27, june, pp. 633-665. Los interesados pueden descargarlo en formato .pdf aquí. Existe una interesante página web desarrollada por el Information Technology Laboratory of the Statistical and Engineering Division en el National Institute for Standards and Technology (NIST). La página contiene unos "Statistical Reference Datasets" (StRD), que son problemas cuyas soluciones se saben correctas, por lo que sirven de contraste a los resultados de los paquetes estadísticos. Es muy recomendable el articulo, en dos partes, de McCullough, titulado "Assessing The Reliability of Statistical Software", que se puede encontrar en la sección "Related Resources and Links" de la página citada. Otra página interesante, alojada en la Universidad de Stanford, contiene un enlace a la batería de test básicos de Wilkinson, conocida como "Statistics Quiz", más un gran número de test adicionales.
Programas y lenguajes de programación recomendados: Como hemos explicado, hay dos aspectos a considerar: primero, programas "enlatados" y segundo, lenguajes de programación más o menos especializados o de propósito general. No obstante, ambas cosas han ido convergiendo en muchos casos. La gran revolución está en los lenguajes de programación con librerías y recursos asociados, gratuitos y distribuidos bajo licencias open source.
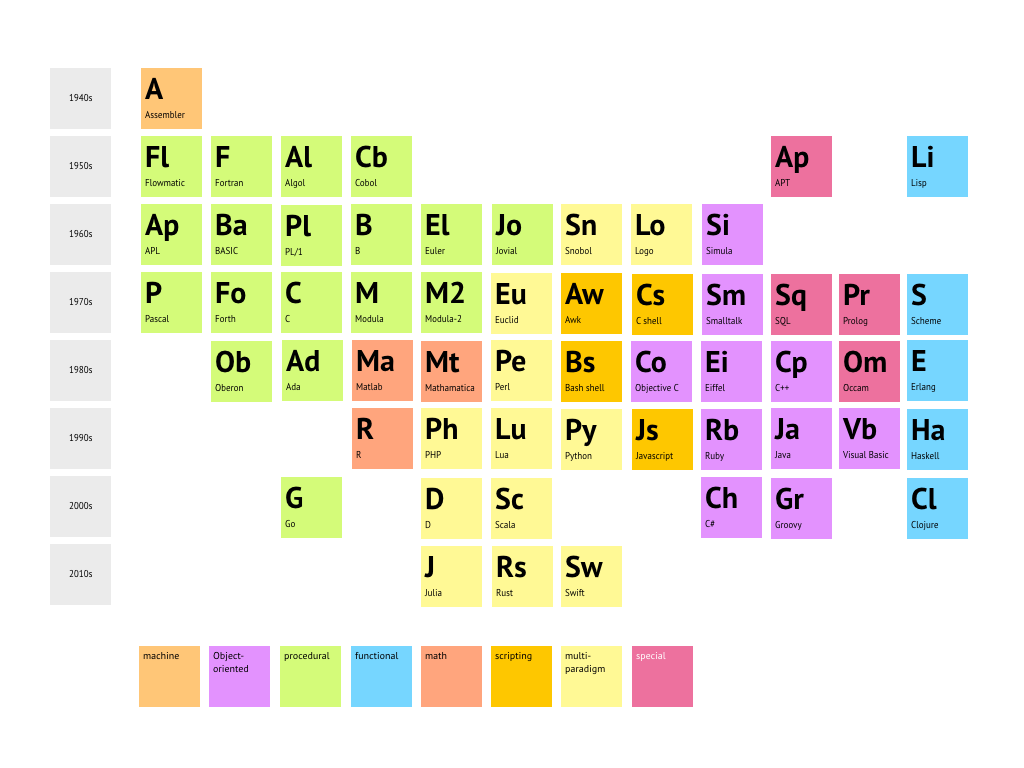
Los lenguajes Fortran, C, BASIC y Pascal pertenecen a la rama de la máquina de Turing, mientras que LISP, Logo, Scheme, Haskell o Clojure pertenecen a la rama del cálculo lambda. La primera da lugar a la programación imperativa y la segunda a la programación declarativa. Las dos grandes ramas están relacionadas, matemáticamente pero también históricamente. El cálculo lambda fue desarrollado en 1928-1929 por Alonzo Church, y se publicó en 1932. La máquina de Turing se desarrolló en 1935-1937 por Alan Turing, y se publicó en 1937. Alan Turing fue estudiante de doctorado de Church en Princeton, de 1936 a 1938. La máquina de Turing y el cálculo lambda tienen una capacidad de computación similar, y cada una de ellas puede simular la otra. No obstante la mayoría de lenguajes en uso hoy son multiparadigma (como Java, imperativo y orientado a objetos, o el moderno Scala, funcional y orientado a objetos). Véase un repaso al tema aquí y más detallado aquí (como puede advertirse, hay formas diferentes de hacer una clasificación). Para una explicación fácilmente comprensible (basada en metáforas) de la diferencia entre programación funcional y orientada a objetos véase esto. Esta relación entre lenguajes y formas de pensar y percibir la realidad está tratada de forma muy sugerente en el fascinante relato corto de Ted Chiang La Historia de tu vida. Existen distintas alternativas para lo que será el lenguaje de programación científico del futuro, y este artículo de Lee Phillips hace un repaso en tres partes a algunas opciones. En la lista tenemos al venerable Fortran (de 1957, aunque ha evolucionado mucho), que se compara con los modernos Haskell (un lenguaje funcional puro), Clojure (una versión moderna del también venerable LISP, de 1958) y Julia (multiparadigma, concebido para ser muy rápido en la ejecución del código). Esta elección de contendientes es un tanto extraña, pues son lenguajes demasiado diferentes con aplicaciones actuales muy distintas (la competencia actual de Fortran es más bien C/C++, Julia compite de momento en el mundo académico, sobre todo con Python). Pero los comentarios de los lectores al artículo de Lee Phillips son muy interesantes, y ayudan a tener una perspectiva más ajustada de los lenguajes disponibles hoy y sus aplicaciones reales. De los analizados por el autor, el que parece tener más potencial de desarrollo futuro en el mundo científico es Julia. El propio Lee Philips lo confirma en este otro artículo escrito seis años después del primero. Un amplio catálogo de lenguajes para uso científico puede consultarse aquí. Julia (https://julialang.org/) es una alternativa a Python como lenguaje de programación científico, más flexible y mucho más rápido, basado en el paradigma de multiple dispatch, que integra y supera la programación funcional y la orientada a objetos, además de ser open source y estar en plena eclosión. Hay ya disponibles librerías de todo tipo, cuyo número no deja de crecer, y que interaccionan entre ellas con total flexibilidad. Los propios creadores de Dynare ya tienen una versión de su software escrito en Julia (véase aquí). La Reserva Federal ha hecho los deberes con su propio modelo de referencia (aquí), aportando además buena documentación. Es recomendable como fuente de información, que agrega novedades de distintos blogs, consultar regularmente Juliabloggers. Una guía muy completa de este lenguaje y su uso en Economía puede encontrarse en Quantitative Economics, escrita por Sargent y Stachurski. Sin embargo, a la hora de elegir un conjunto de aplicaciones para trabajar con Julia yo seguiría las recomendaciones de Sargent y Stachurski. Buenos entornos integrados para el desarrollo (IDE) son Juno (https://junolab.org/), VS Code (https://code.visualstudio.com/) o JuliaWin (https://github.com/heetbeet/juliawin). Por su parte, R es un lenguaje de programación con gran cantidad de desarrollos especializados en el ámbito científico, especialmente la estadística y el tratamiento de datos, desarrollado bajo licencia GNU (http://www.r-project.org/). Puede considerarse una implementación distinta del lenguaje de programación S, desarrollado por los Laboratorios Bell (AT&T). Es gratituito, excepcionalmente potente, extensible y, además, es aún hoy la herramienta de estadística más extendida y utilizada por los investigadores de todo el mundo. Es recomendable el programa basado en R llamado RStudio (http://www.rstudio.com/), que permite instalar fácilmente módulos que amplían sus posibilidades. Esta entrada de Fernández-Villaverde en Nada es Gratis es un buen primer paso para orientarse. También es una buena guía para iniciarse esta otra https://www.r-bloggers.com/how-to-learn-r-2/ entrada del estupendo agregador de blogs R-Bloggers. Se puede trabajar con modelos DSGE en R con ayuda de gEcon, como se cuenta aquí. Con con R se puede hacer de todo, no es de extrañar que también podamos trabajar en modelos basados en agentes (ABMs), usando el lenguaje NetLogo con el paquete RNetLogo. De esto hablaremos un poco más abajo. R y Python son lenguajes de código abierto, cuyo origen se sitúa en los años 90, y que hoy tienen acumulada una enorme cantidad de recursos disponibles, a diferencia de Julia, que es un lenguaje muy reciente que apareció en 2012. Python es hoy el lenguaje de moda, el más empleado en la actualidad en todo el mundo en aplicaciones científicas e industriales, y muchos desarrollos en inteligencia artificial y machine learning se hacen con él (complementado en ocasiones con código en C/C++ o en Fortran, cuando se requiere velocidad de ejecución). Pero las limitaciones de Python (velocidad de ejecución, uso de memoria, paralelismo) están impulsando la búsqueda de soluciones y alternativas. Se han tratado de implementar dos tipos de soluciones. La primera es hacer accesibles a Python el código escrito en C. Librerías computacionalmente muy intensivas como Tensorflow están escritas en C con wrappers que proporcionan una interfaz en Python. La segunda solución es Pypy (https://www.pypy.org) que permite compilar el código Python y generar ejecutables. Parece que ambas vías para superar las limitaciones de Python se han fusionado en CFFI (https://cffi.readthedocs.io/en/latest/). Las alternativas pasan por un lenguaje de programación más moderno, y empezar desde cero. Google ha elegido Swift como lenguaje de programación moderno para reemplazar Python en el tratamiento masivo de datos y machine learning (descartando otras opciones como Julia o Rust, este último desarrollado por Mozilla). Swift es el lenguaje, ahora open source, utilizado por Apple para el desarrollo de aplicaciones. El enorme respaldo corporativo de Swift y sus características auguran que este pueda ser el lenguaje del futuro en aplicaciones industriales en las que hoy se usa Python, y que eso acabe arrastrando al mundo académico y científico. En todo caso hay una carrera desatada para enterrar Python (y eventualmente C/C++ y Fortran) y sustituirlo por una herramienta más moderna, y está por ver qué lenguaje será el sucesor. *** Para los Agent-Based Models (ABM, o ACE para Agent-Based Computational Economics) un programa y lenguaje de programación especializado muy extendido es NetLogo (https://ccl.northwestern.edu/netlogo/), basado en Logo, que es a su vez un dialecto de LISP. Es sencillo de aprender pero muy capaz, la documentación es abundante y es quizás la mejor forma de empezar. Aunque NetLogo es un lenguaje que se ejecuta compilado sobre la Máquina Virtual Java, y no es lento, su única limitación de peso está relacionada con la paralelización. Los programas de NetLogo corren sobre un procesador de un ordenador, en bloque. No puedes dividir el programa en hilos y hacerlos correr paralelamente en distintos procesadores u ordenadores. Esto quiere decir que si tienes un programa complejo (léase, largo) y simulas con muchos agentes (decenas de miles, cientos de miles o incluso millones), cada paso puede llevar bastante tiempo, sobre todo si el código no está debidamente afinado. NetLogo no ofrece de momento posibilidades de paralelización, pero sí existen herramientas como BehaviourSpace (dentro del propio NetLogo) y RNetLogo (desde R) que sirven para experimentar ejecutando un mismo programa a la vez en varias máquinas con distintos conjuntos de parámetros. Para estos temas de optimización de código, velocidad de ejecución y experimentación, puede leerse este artículo. Además de NetLogo, en el desarrollo de los ABMs se pueden usar muchos lenguajes distintos, como los genéricos C++ o Java y otros más especializados. Precisamente para desarrollar ABMs con Java uno de los programas más usados es RePast (https://repast.github.io/), aunque se pueden citar también MASON (http://cs.gmu.edu/~eclab/projects/mason/) o JADE (http://jade.tilab.com/). MESA (https://mesa.readthedocs.io/en/master/) es una alternativa a las herramientas mencionadas, basada en Python en vez de Java o NetLogo. El uso de actores en Scala, a partir de la librería AKKA, podría ser también una alternativa. Julia tiene ya un framework llamado Agents (https://github.com/JuliaDynamics/Agents.jl). Por último, en Swift existe el GameplayKit (https://developer.apple.com/documentation/gameplaykit), que podría proporcionar una base. Un extenso repaso a casi todas las opciones puede encontrarse aquí y en este otro artículo. Resulta muy interesante la web del profesor de la Universidad de Sevilla Fernando Sancho Caparrini, para temas de programación en general, para introducirse en la inteligencia artificial o el aprendizaje automático, pero también para encontrar recursos para trabajar con Netlogo. *** En suma, para la Economía: MATLAB (modelización matemática, gratuito si usamos Octave) y R (estadística y tratamiento de datos) fueron los estándares en el mundo académico y científico (R aún lo es en su ámbito). La referencia actual en el mundo científico y empresarial/industrial es Python (junto a C/C++ y Fortran). Pero las limitaciones de Python explican que se le estén buscando alternativas. Julia se está convirtiendo en el lenguaje de moda en el mundo académico, aunque en algunos temas (inteligencia artificial, machine learning) las aplicaciones industriales/comerciales son la clave, y aquí Swift tiene el respaldo de Google y de Apple. Para modelos basados en agentes heterogéneos, recomendaría empezar con NetLogo, sobre todo si no se tiene experiencia previa con lenguajes de programación, y después, si fuera necesario, considerar el uso de otros lenguajes de propósito general y librerías asociadas (Python, Julia, Swift). *** Resulta sorprendente comprobar con qué facilidad los chats de inteligencia artificial (AI) y las herramientas especializadas basadas en AI son capaces de programar o revisar código en casi cualquier lenguaje. Jesús Fernández-Villaverde tiene dos valiosísimos artículos, divulgativos pero de gran calidad, sobre la inteligencia artificial y los algoritmos de aprendizaje automático (machine learning), el primero (La economía de la inteligencia artificial: unas ideas básicas) dedicado a tratar de explica qué es el aprendizaje automático y el segundo (La inteligencia artificial y el futuro del crecimiento económico) a evaluar las posibles consecuencias económicas de estos avances, especialmente en lo relativo al crecimiento económico.
Alternativas y complementos: Stata, de Stata Corporation (www.stata.com), es un gran programa estadístico con estimaciones pre-programadas, es decir, un "paquete enlatado", pero en su clase es de lejos el mejor, e incluye un lenguaje de programación propio (MATA) que multiplica sus posibilidades. En conjunto, es una herramienta integrada y muy, muy potente para el tratamiento de datos y la estimación, rápida, bien diseñada, fácil de usar y en definitiva muy empleada en investigación con microeconometría. Pero sus capacidades van más allá, e incluye incluso cosas como el tratamiento sencillo de modelos de equilibrio general dinámico estocástico (DSGEs), con estimación bayesiana incorporada. Es un programa de pago, pero no especialmente caro. The Stata Blog tiene interesantes mini-tutoriales. A pesar de sus innegables virtudes, muchos han ido pasándose a R en los últimos años. MATLAB, de Mathworks Inc. (www.mathworks.com) fue la referencia y el estándar para la modelización económica. Básicamente es un lenguaje de programación orientado a la modelización y el cálculo numérico, con origen en los años 80. El programa en sí es de pago, y bastante caro si sumamos todos los módulos y herramientas, pero tiene un clon gratuito y bajo licencia GNU, llamado Octave (http://www.gnu.org/software/octave/), que tiene no obstante limitaciones. Sobre MATLAB (o bien Octave) corre Dynare, que es un programa gratuito multiplataforma para la estimación de modelos de equilibrio general dinámico estocástico (dynamic stochastic general equilibrium models, DSGE). Para introducirse en este tema, recomiendo el libro de Torres del que hablo en esta página. *** Una alternativa interesante a lo que acabo de recomendar es el programa, con potente lenguaje de programación asociado, Mathematica (www.wolfram.com). Esta aplicación es cara, y ese es su principal problema. GAUSS (www.aptech.com) es otra aplicación con lenguaje de programación asociado, similar -a grandes rasgos- a MATLAB. Pero es también un programa de pago, su base de usuarios no es muy grande y se ha ido reduciendo aún más con el tiempo. Una alternativa a Stata como "programa enlatado", aunque menos capaz, podría ser Eviews (www.eviews.com, en origen el antiguo MicroTSP, pero con una cómoda interfaz de usuario). Es de pago, pero no demasiado caro, y tiene versiones muy asequibles para profesores y estudiantes (incluso una gratuita, pero muy limitada, para estos). GRETL es una aplicación multiplataforma distribuida bajo una licencia de código abierto (http://gretl.sourceforge.net/gretl_espanol.html), y que los estudiantes pueden utilizar para sus trabajos, ya que tiene una interfaz intuitiva y es suficientemente completa para hacer muchas cosas. BUGS es otra aplicación de código abierto, pero para inferencia bayesiana (https://www.mrc-bsu.cam.ac.uk/software/bugs/). Por último queda mencionar otros programas que pueden ser útiles (o no, según las necesidades). El SAS/STAT (www.sas.com) es muy completo (con él se puede hacer de todo lo relacionado con la estadística y la gestión de datos), gracias a sus muchos módulos, y ahora existe una "university edition" gratuita, con versiones para Windows, Linux y OS X. Un buen programa para el análisis estadístico de datos y presentación de resultados es IBM SPSS Statistics (antiguo SPSS a secas, www.spss.com/), que tiene competencia en JMP (de la empresa que desarrolla SAS, www.jmp.com). Puede ser de utilidad como complemento el programa Stat/Transfer, para conversión de unos formatos de archivos de bases de datos y programas estadísticos en otros (www.stattransfer.com). Un programa gratuito muy interesante, que uso para generar fácilmente gráficos, entre otras cosas, es Maxima (http://maxima.sourceforge.net/es/). Por último Scientific Word (www.mackichan.com), para la elaboración de documentos científicos empleando LaTeX. La empresa ha cerrado pero ofrecen el programa gratis, y han hecho público el código en Github (https://github.com/ScientificWord). Es muy interesante y recomendable también Compositor (http://compositorapp.com/), pero sólo disponible para Mac y con el desarrollo recientemente retomado después de un período de abandono.
|